![]()
[Apr-2024] Get 100% Real Free Databricks Certification Databricks-Certified-Professional-Data-Engineer Sample Questions
Accurate Databricks-Certified-Professional-Data-Engineer Questions with Free and Fast Updates
Databricks Certified Professional Data Engineer certification exam is designed for data engineers who work with Databricks. Databricks-Certified-Professional-Data-Engineer exam tests the candidate's ability to design, build, and maintain data pipelines, as well as their knowledge of various data engineering tools and techniques. Databricks-Certified-Professional-Data-Engineer exam is intended to validate the candidate's proficiency in using Databricks for data engineering tasks.
Databricks Certified Professional Data Engineer (Databricks-Certified-Professional-Data-Engineer) exam is a certification program designed to validate the skills and expertise of data engineers in developing and managing big data pipelines using Databricks. Databricks-Certified-Professional-Data-Engineer exam is ideal for data engineers, ETL developers, and data architects who work with Databricks and want to showcase their skills and proficiency.
Databricks is a powerful data engineering and machine learning platform that is widely used across various industries. To ensure that professionals have the necessary skills and expertise to work with Databricks, the company offers a certification program. One of the certifications offered is the Databricks Certified Professional Data Engineer exam, also known as the Databricks Databricks-Certified-Professional-Data-Engineer exam.
NEW QUESTION # 27
The data engineer team has been tasked with configured connections to an external database that does not have a supported native connector with Databricks. The external database already has data security configured by group membership. These groups map directly to user group already created in Databricks that represent various teams within the company.
A new login credential has been created for each group in the external database. The Databricks Utilities Secrets module will be used to make these credentials available to Databricks users.
Assuming that all the credentials are configured correctly on the external database and group membership is properly configured on Databricks, which statement describes how teams can be granted the minimum necessary access to using these credentials?
- A. ''Read'' permissions should be set on a secret key mapped to those credentials that will be used by a given team.
- B. No additional configuration is necessary as long as all users are configured as administrators in the workspace where secrets have been added.
- C. "Manage" permission should be set on a secret scope containing only those credentials that will be used by a given team.
- D. "Read" permissions should be set on a secret scope containing only those credentials that will be used by a given team.
Answer: D
Explanation:
In Databricks, using the Secrets module allows for secure management of sensitive information such as database credentials. Granting 'Read' permissions on a secret key that maps to database credentials for a specific team ensures that only members of that team can access these credentials. This approach aligns with the principle of least privilege, granting users the minimum level of access required to perform their jobs, thus enhancing security.
References:
* Databricks Documentation on Secret Management: Secrets
NEW QUESTION # 28
In order to facilitate near real-time workloads, a data engineer is creating a helper function to leverage the schema detection and evolution functionality of Databricks Auto Loader. The desired function willautomatically detect the schema of the source directly, incrementally process JSON files as they arrive in a source directory, and automatically evolve the schema of the table when new fields are detected.
The function is displayed below with a blank:
Which response correctly fills in the blank to meet the specified requirements?
- A. Option C
- B. Option E
- C. Option B
- D. Option D
- E. Option A
Answer: C
Explanation:
Explanation
Option B correctly fills in the blank to meet the specified requirements. Option B uses the
"cloudFiles.schemaLocation" option, which is required for the schema detection and evolution functionality of Databricks Auto Loader. Additionally, option B uses the "mergeSchema" option, which is required for the schema evolution functionality of Databricks Auto Loader. Finally, option B uses the "writeStream" method, which is required for the incremental processing of JSON files as they arrive in a source directory. The other options are incorrect because they either omit the required options, use the wrong method, or use the wrong format. References:
Configure schema inference and evolution in Auto Loader:
https://docs.databricks.com/en/ingestion/auto-loader/schema.html
Write streaming data:
https://docs.databricks.com/spark/latest/structured-streaming/writing-streaming-data.html
NEW QUESTION # 29
A table is registered with the following code:
Bothusersandordersare Delta Lake tables. Which statement describes the results of queryingrecent_orders?
- A. All logic will execute when the table is defined and store the result of joining tables to the DBFS; this stored data will be returned when the table is queried.
- B. All logic will execute at query time and return the result of joining the valid versions of the source tables at the time the query began.
- C. Results will be computed and cached when the table is defined; these cached results will incrementally update as new records are inserted into source tables.
- D. The versions of each source table will be stored in the table transaction log; query results will be saved to DBFS with each query.
- E. All logic will execute at query time and return the result of joining the valid versions of the source tables at the time the query finishes.
Answer: A
NEW QUESTION # 30
Two of the most common data locations on Databricks are the DBFS root storage and external object storage mounted with dbutils.fs.mount().
Which of the following statements is correct?
- A. Neither the DBFS root nor mounted storage can be accessed when using %sh in a Databricks notebook.
- B. DBFS is a file system protocol that allows users to interact with files stored in object storage using syntax and guarantees similar to Unix file systems.
- C. By default, both the DBFS root and mounted data sources are only accessible to workspace administrators.
- D. The DBFS root is the most secure location to store data, because mounted storage volumes must have full public read and write permissions.
- E. The DBFS root stores files in ephemeral block volumes attached to the driver, while mounted directories will always persist saved data to external storage between sessions.
Answer: B
Explanation:
DBFS is a file system protocol that allows users to interact with files stored in object storage using syntax and guarantees similar to Unix file systems1. DBFS is not a physical file system, but a layer over the object storage that provides a unified view of data across different data sources1. By default, the DBFS root is accessible to all users in the workspace, and the access to mounted data sources depends on the permissions of the storage account or container2. Mounted storage volumes do not need to have full public read and write permissions, but they do require a valid connection string or access key to be provided when mounting3. Both the DBFS root and mounted storage can be accessed when using %sh in a Databricks notebook, as long as the cluster has FUSE enabled4. The DBFS root does not store files in ephemeral block volumes attached to the driver, but in the object storage associated with the workspace1. Mounted directories will persist saved data to external storage between sessions, unless they are unmounted or deleted3. References: DBFS, Work with files on Azure Databricks, Mounting cloudobject storage on Azure Databricks, Access DBFS with FUSE
NEW QUESTION # 31
All records from an Apache Kafka producer are being ingested into a single Delta Lake table with the following schema:
key BINARY, value BINARY, topic STRING, partition LONG, offset LONG, timestamp LONG There are 5 unique topics being ingested. Only the "registration" topic contains Personal Identifiable Information (PII). The company wishes to restrict access to PII. The company also wishes to only retain records containing PII in this table for 14 days after initial ingestion. However, for non-PII information, it would like to retain these records indefinitely.
Which of the following solutions meets the requirements?
- A. Data should be partitioned by the topic field, allowing ACLs and delete statements to leverage partition boundaries.
- B. Separate object storage containers should be specified based on the partition field, allowing isolation at the storage level.
- C. Data should be partitioned by the registration field, allowing ACLs and delete statements to be set for the PII directory.
- D. All data should be deleted biweekly; Delta Lake's time travel functionality should be leveraged to maintain a history of non-PII information.
- E. Because the value field is stored as binary data, this information is not considered PII and no special precautions should be taken.
Answer: A
Explanation:
Explanation
Partitioning the data by the topic field allows the company to apply different access control policies and retention policies for different topics. For example, the company can use the Table Access Control feature to grant or revoke permissions to the registration topic based on user roles or groups. The company can also use the DELETE command to remove records from the registration topic that are older than 14 days, while keeping the records from other topics indefinitely. Partitioning by the topic field also improves the performance of queries that filter by the topic field, as they can skip reading irrelevant partitions. References:
Table Access Control: https://docs.databricks.com/security/access-control/table-acls/index.html DELETE: https://docs.databricks.com/delta/delta-update.html#delete-from-a-table
NEW QUESTION # 32
The default threshold of VACUUM is 7 days, internal audit team asked to certain tables to maintain at least
365 days as part of compliance requirement, which of the below setting is needed to implement.
- A. MODIFY TABLE table_name set TBLPROPERTY (delta.maxRetentionDays = 'inter-val 365 days')
- B. ALTER TABLE table_name set EXENDED TBLPROPERTIES (del-ta.deletedFileRetentionDuration=
'interval 365 days') - C. ALTER TABLE table_name set TBLPROPERTIES (del-ta.deletedFileRetentionDuration= 'interval 365 days')
- D. ALTER TABLE table_name set EXENDED TBLPROPERTIES (delta.vaccum.duration= 'interval 365 days')
Answer: C
Explanation:
Explanation
1.ALTER TABLE table_name SET TBLPROPERTIES ( property_key [ = ] property_val [, ...] ) TBLPROPERTIES allow you to set key-value pairs Table properties and table options (Databricks SQL) | Databricks on AWS
NEW QUESTION # 33
You were asked to create or overwrite an existing delta table to store the below transaction data.
- A. 1.CREATE OR REPLACE TABLE transactions (
2.transactionId int,
3.transactionDate timestamp,
4.unitsSold int) - B. 1.CREATE IF EXSITS REPLACE TABLE transactions (
2.transactionId int,
3.transactionDate timestamp,
4.unitsSold int) - C. 1.CREATE OR REPLACE DELTA TABLE transactions (
2.transactionId int,
3.transactionDate timestamp,
4.unitsSold int) - D. 1.CREATE OR REPLACE TABLE IF EXISTS transactions (
2.transactionId int,
3.transactionDate timestamp,
4.unitsSold int)
5.FORMAT DELTA
Answer: A
Explanation:
Explanation
The answer is
1.CREATE OR REPLACE TABLE transactions (
2.transactionId int,
3.transactionDate timestamp,
4.unitsSold int)
When creating a table in Databricks by default the table is stored in DELTA format.
NEW QUESTION # 34
What type of table is created when you create delta table with below command?
CREATE TABLE transactions USING DELTA LOCATION "DBFS:/mnt/bronze/transactions"
- A. Managed table
- B. Managed delta table
- C. Temp table
- D. External table
- E. Delta Lake table
Answer: D
Explanation:
Explanation
Anytime a table is created using the LOCATION keyword it is considered an external table, below is the current syntax.
Syntax
CREATE TABLE table_name ( column column_data_type...) USING format LOCATION "dbfs:/" format -> DELTA, JSON, CSV, PARQUET, TEXT I created the table command based on the above question, you can see it created an external table,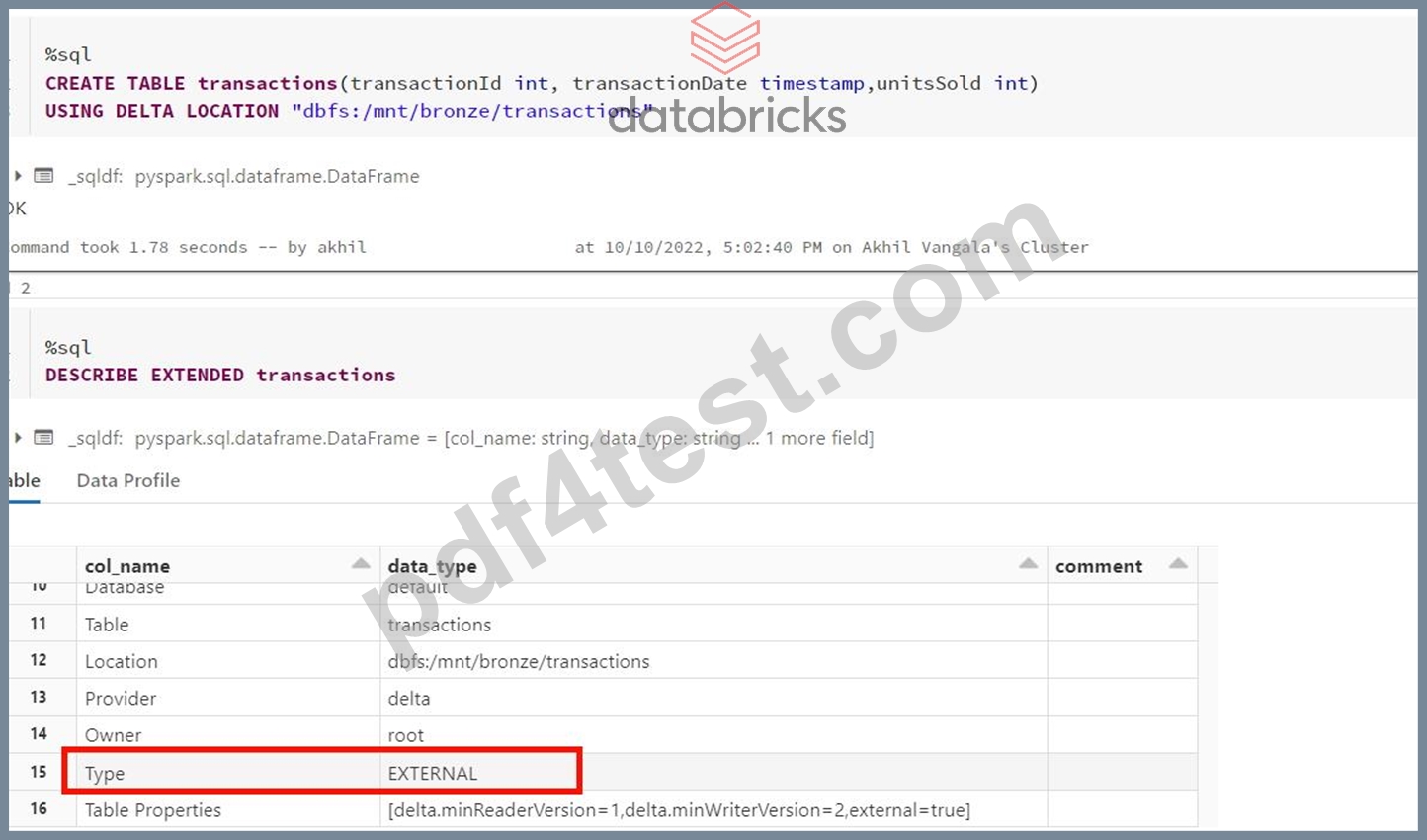
NEW QUESTION # 35
You are asked to setup an AUTO LOADER to process the incoming data, this data arrives in JSON format and get dropped into cloud object storage and you are required to process the data as soon as it arrives in cloud storage, which of the following statements is correct
- A. AUTO LOADER has to be triggered from an external process when the file arrives in the cloud storage
- B. AUTO LOADER needs to be converted to a Structured stream process
- C. AUTO LOADER can support file notification method so it can process data as it arrives
- D. AUTO LOADER can only process continuous data when stored in DELTA lake
- E. AUTO LOADER is native to DELTA lake it cannot support external cloud object storage
Answer: C
Explanation:
Explanation
Auto Loader supports two modes when ingesting new files from cloud object storage Directory listing: Auto Loader identifies new files by listing the input directory, and uses a directory polling approach.
File notification: Auto Loader can automatically set up a notification service and queue service that subscribe to file events from the input directory.
Diagram Description automatically generated
File notification is more efficient and can be used to process the data in real-time as data arrives in cloud object storage.
Choosing between file notification and directory listing modes | Databricks on AWS
NEW QUESTION # 36
Which of the following scenarios is the best fit for the AUTO LOADER solution?
- A. Incrementally process new data from relational databases like MySQL
- B. Efficiently copy data from data lake location to another data lake location
- C. Efficiently move data incrementally from one delta table to another delta table
- D. Incrementally process new streaming data from Apache Kafa into delta lake
- E. Efficiently process new data incrementally from cloud object storage
Answer: E
Explanation:
Explanation
The answer is, Efficiently process new data incrementally from cloud object storage.
Please note: AUTO LOADER only works on data/files located in cloud object storage like S3 or Azure Blob Storage it does not have the ability to read other data sources, although AU-TO LOADER is built on top of structured streaming it only supports files in the cloud object stor-age. If you want to use Apache Kafka then you can just use structured streaming.
Diagram Description automatically generated
Auto Loader and Cloud Storage Integration
Auto Loader supports a couple of ways to ingest data incrementally
1.Directory listing - List Directory and maintain the state in RocksDB, supports incremental file listing
2.File notification - Uses a trigger+queue to store the file notification which can be later used to retrieve the file, unlike Directory listing File notification can scale up to millions of files per day.
[OPTIONAL]
Auto Loader vs COPY INTO?
Auto Loader
Auto Loader incrementally and efficiently processes new data files as they arrive in cloud storage without any additional setup. Auto Loader provides a new Structured Streaming source called cloudFiles. Given an input directory path on the cloud file storage, the cloudFiles source automatically processes new files as they arrive, with the option of also processing existing files in that directory.
When to use Auto Loader instead of the COPY INTO?
*You want to load data from a file location that contains files in the order of millions or higher. Auto Loader can discover files more efficiently than the COPY INTO SQL command and can split file processing into multiple batches.
*You do not plan to load subsets of previously uploaded files. With Auto Loader, it can be more difficult to reprocess subsets of files. However, you can use the COPY INTO SQL command to reload subsets of files while an Auto Loader stream is simultaneously running.
Refer to more documentation here,
https://docs.microsoft.com/en-us/azure/databricks/ingestion/auto-loader
NEW QUESTION # 37
A junior member of the data engineering team is exploring the language interoperability of Databricks notebooks. The intended outcome of the below code is to register a view of all sales that occurred in countries on the continent of Africa that appear in thegeo_lookuptable.
Before executing the code, runningSHOWTABLESon the current database indicates the database contains only two tables:geo_lookupandsales.
Which statement correctly describes the outcome of executing these command cells in order in an interactive notebook?
- A. Cmd 1 will succeed and Cmd 2 will fail, countries at will be a Python variable representing a PySpark DataFrame.
- B. Both commands will fail. No new variables, tables, or views will be created.
- C. Cmd 1 will succeed. Cmd 2 will search all accessible databases for a table or view named countries af: if this entity exists, Cmd 2 will succeed.
- D. Cmd 1 will succeed and Cmd 2 will fail, countries at will be a Python variable containing a list of strings.
- E. Both commands will succeed. Executing show tables will show that countries at and sales at have been registered as views.
Answer: D
Explanation:
This is the correct answer because Cmd 1 is written in Python and uses a list comprehension to extract the country names from the geo_lookup table and store them in a Python variable named countries af. This variable will contain a list of strings, not a PySpark DataFrame or a SQL view. Cmd 2 is written in SQL and tries to create a view named sales af by selecting from the sales table where city is in countries af. However, this command will fail because countries af is not a valid SQL entity and cannot be used in a SQL query. To fix this, a better approach would be to use spark.sql() to execute a SQL query in Python and pass the countries af variable as a parameter. Verified References: [Databricks Certified Data Engineer Professional], under
"Language Interoperability" section; Databricks Documentation, under "Mix languages" section.
NEW QUESTION # 38
You are currently asked to work on building a data pipeline, you have noticed that you are currently working on a very large scale ETL many data dependencies, which of the following tools can be used to address this problem?
- A. JOBS and TASKS
- B. SQL Endpoints
- C. AUTO LOADER
- D. STRUCTURED STREAMING with MULTI HOP
- E. DELTA LIVE TABLES
Answer: E
Explanation:
Explanation
The answer is, DELTA LIVE TABLES
DLT simplifies data dependencies by building DAG-based joins between live tables. Here is a view of how the dag looks with data dependencies without additional meta data,
1.create or replace live view customers
2.select * from customers;
3.
4.create or replace live view sales_orders_raw
5.select * from sales_orders;
6.
7.create or replace live view sales_orders_cleaned
8.as
9.select sales.* from
10.live.sales_orders_raw s
11. join live.customers c
12.on c.customer_id = s.customer_id
13.where c.city = 'LA';
14.
15.create or replace live table sales_orders_in_la
16.selects from sales_orders_cleaned;
Above code creates below dag
Documentation on DELTA LIVE TABLES,
https://databricks.com/product/delta-live-tables
https://databricks.com/blog/2022/04/05/announcing-generally-availability-of-databricks-delta-live-tables-dlt.htm DELTA LIVE TABLES, addresses below challenges when building ETL processes
1.Complexities of large scale ETL
a.Hard to build and maintain dependencies
b.Difficult to switch between batch and stream
2.Data quality and governance
a.Difficult to monitor and enforce data quality
b.Impossible to trace data lineage
3.Difficult pipeline operations
a.Poor observability at granular data level
b.Error handling and recovery is laborious
NEW QUESTION # 39
A distributed team of data analysts share computing resources on an interactive cluster with autoscaling configured. In order to better manage costs and query throughput, the workspace administrator is hoping to evaluate whether cluster upscaling is caused by many concurrent users or resource-intensive queries.
In which location can one review the timeline for cluster resizing events?
- A. Workspace audit logs
- B. Cluster Event Log
- C. Executor's log file
- D. Driver's log file
- E. Ganglia
Answer: B
NEW QUESTION # 40
The data analyst team had put together queries that identify items that are out of stock based on orders and replenishment but when they run all together for final output the team noticed it takes a really long time, you were asked to look at the reason why queries are running slow and identify steps to improve the performance and when you looked at it you noticed all the code queries are running sequentially and using a SQL endpoint cluster. Which of the following steps can be taken to resolve the issue?
Here is the example query
1.--- Get order summary
2.create or replace table orders_summary
3.as
4.select product_id, sum(order_count) order_count
5.from
6. (
7. select product_id,order_count from orders_instore
8. union all
9. select product_id,order_count from orders_online
10. )
11.group by product_id
12.-- get supply summary
13.create or repalce tabe supply_summary
14.as
15.select product_id, sum(supply_count) supply_count
16.from supply
17.group by product_id
18.
19.-- get on hand based on orders summary and supply summary
20.
21.with stock_cte
22.as (
23.select nvl(s.product_id,o.product_id) as product_id,
24. nvl(supply_count,0) - nvl(order_count,0) as on_hand
25.from supply_summary s
26.full outer join orders_summary o
27. on s.product_id = o.product_id
28.)
29.select *
30.from
31.stock_cte
32.where on_hand = 0
- A. Turn on the Serverless feature for the SQL endpoint and change the Spot Instance Pol-icy to "Reliability Optimized."
- B. Increase the cluster size of the SQL endpoint.
- C. Increase the maximum bound of the SQL endpoint's scaling range.
- D. Turn on the Auto Stop feature for the SQL endpoint.
- E. Turn on the Serverless feature for the SQL endpoint.
Answer: B
Explanation:
Explanation
The answer is to increase the cluster size of the SQL Endpoint, here queries are running sequentially and since the single query can not span more than one cluster adding more clusters won't improve the query but rather increasing the cluster size will improve performance so it can use additional compute in a warehouse.
In the exam please note that additional context will not be given instead you have to look for cue words or need to understand if the queries are running sequentially or concurrently. if the que-ries are running sequentially then scale up(more nodes) if the queries are running concurrently (more users) then scale out(more clusters).
Below is the snippet from Azure, as you can see by increasing the cluster size you are able to add more worker nodes.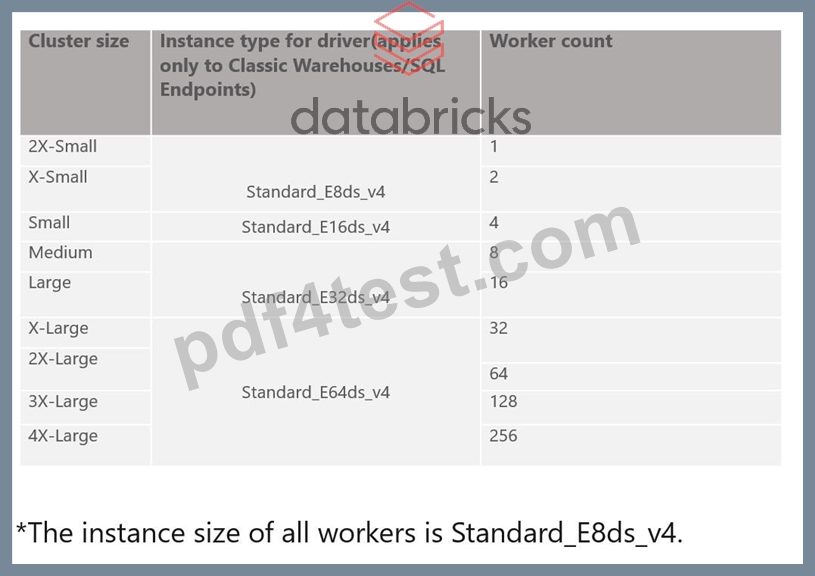
SQL endpoint scales horizontally(scale-out) and vertically (scale-up), you have to understand when to use what.
Scale-up-> Increase the size of the cluster from x-small to small, to medium, X Large....
If you are trying to improve the performance of a single query having additional memory, additional nodes and cpu in the cluster will improve the performance.
Scale-out -> Add more clusters, change max number of clusters
If you are trying to improve the throughput, being able to run as many queries as possible then having an additional cluster(s) will improve the performance.
SQL endpoint
A picture containing diagram Description automatically generated
NEW QUESTION # 41
Kevin is the owner of the schema sales, Steve wanted to create new table in sales schema called regional_sales so Kevin grants the create table permissions to Steve. Steve creates the new table called regional_sales in sales schema, who is the owner of the table regional_sales
- A. By default ownership is assigned DBO
- B. Steve is the owner of the table
- C. By default ownership is assigned to DEFAULT_OWNER
- D. Kevin and Smith both are owners of table
- E. Kevin is the owner of sales schema, all the tables in the schema will be owned by Kevin
Answer: B
Explanation:
Explanation
A user who creates the object becomes its owner, does not matter who is the owner of the parent object.
NEW QUESTION # 42
Which of the statements are incorrect when choosing between lakehouse and Datawarehouse?
- A. Lakehouse can have special indexes and caching which are optimized for Machine learning
- B. Traditional Data warehouses have storage and compute are coupled.
- C. Lakehouse uses standard data formats like Parquet.
- D. Lakehouse cannot serve low query latency with high reliability for BI workloads, only suitable for batch workloads.
- E. Lakehouse can be accessed through various API's including but not limited to Py-thon/R/SQL
Answer: D
Explanation:
Explanation
The answer is Lakehouse cannot serve low query latency with high reliability for BI workloads, only suitable for batch workloads.
Lakehouse can replace traditional warehouses by leveraging storage and compute optimizations like caching to serve them with low query latency with high reliability.
Focus on comparisons between Spark Cache vs Delta Cache.
https://docs.databricks.com/delta/optimizations/delta-cache.html
What Is a Lakehouse? - The Databricks Blog
Graphical user interface, text, application Description automatically generated
Bottom of Form
Top of Form
NEW QUESTION # 43
......
Databricks-Certified-Professional-Data-Engineer Study Guide Realistic Verified Dumps: https://testking.pdf4test.com/Databricks-Certified-Professional-Data-Engineer-actual-dumps.html